
Inference caching in LLMs is emerging as one of the most effective ways to control rising AI infrastructure costs while improving response speed. As large language models move from experimentation to production, organizations are realizing that repeated computations, processing the same prompts, documents, and queries, create unnecessary overhead.
Inference caching in LLMs solves this problem by reusing previously computed results instead of generating them from scratch each time. By intelligently storing and retrieving intermediate states or final outputs, it reduces redundant processing, lowers token consumption, and significantly improves latency in real-world applications.
Are your AI infrastructure costs up 320% in two years, even as token prices keep falling, while inference now accounts for 55–80% of GPU spend? This trend shows that inference has become the dominant slice of enterprise GPU spend as models move from training into production.
The paradox is stark: Per-token costs have dropped roughly 280-fold since 2022, yet total AI bills are surging because usage is growing faster than costs are falling.
Redundant recomputation of static context - unchanged prompts, documents, and instructions drive much of this, wasting significant tokens in repeated interactions.
Inference caching counters this by storing intermediate states, such as KV pairs, for reuse, yielding 60–90% compute savings and faster time-to-first-token with no accuracy loss on exact cached content.
Knolli makes this enterprise viable via metadata automation: Pinpointing cacheable content, enforcing automatic invalidation, and securing multi-tenant isolation, proven in deployments achieving substantial cost reductions.
Inference Caching optimizes Large Language Models (LLMs) deployments by storing intermediate computations from prior queries, avoiding redundant work on repeated or similar inputs.
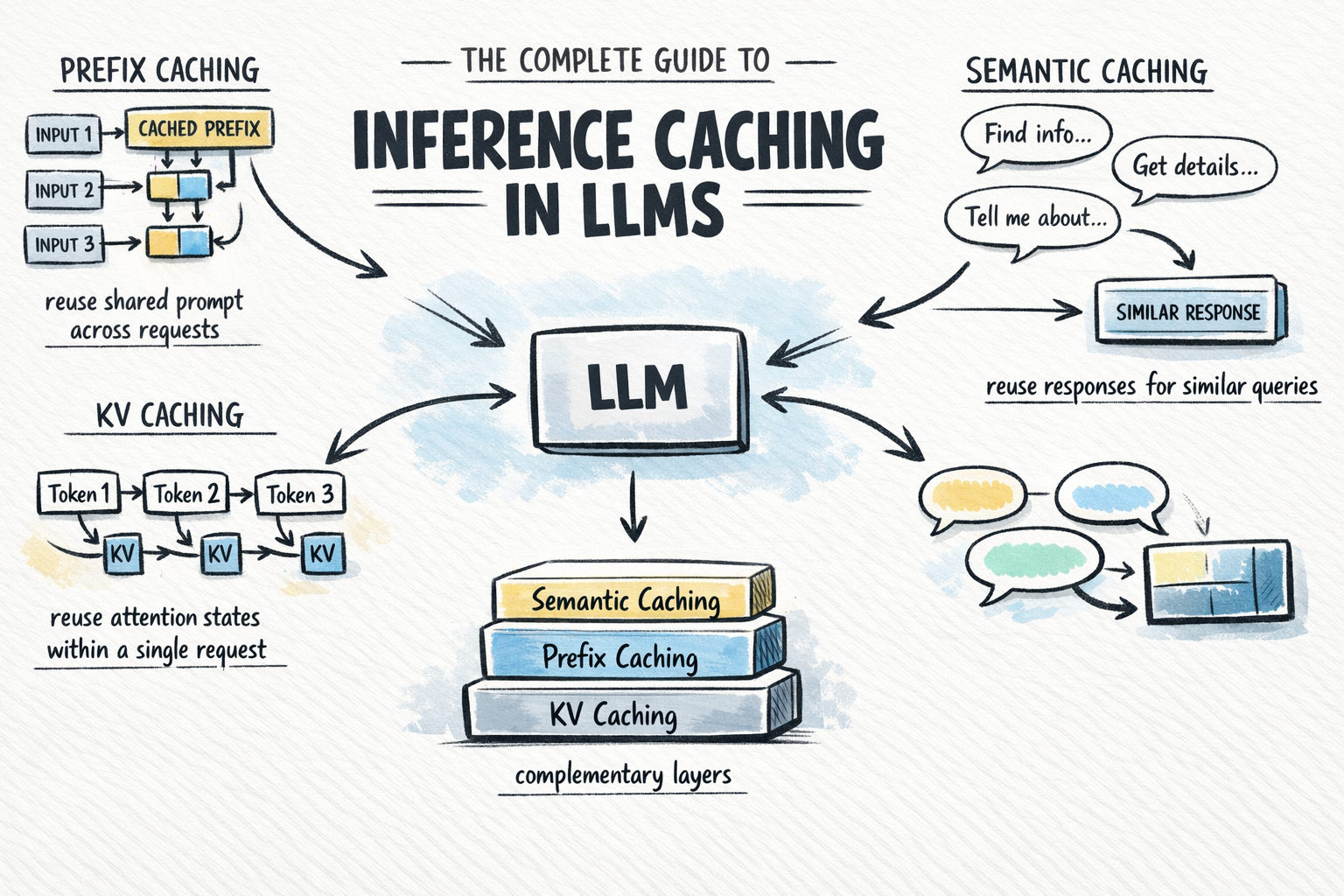
Key types include:
1. KV/Prefix Caching: Reuses KV states for shared prompt prefixes (e.g., system instructions, docs). The first call computes; exact match prompts skip recomputation, cutting costs 50–90% and time-to-first-token. Because the computation is mathematically reused, there is zero accuracy loss. This pattern is widely implemented in high-performance inference engines such as those based on vLLM.
2. Semantic Caching: Application-level; matches new input queries against previously seen queries by semantic similarity (via embeddings), and returns a stored response when similarity exceeds a threshold—bypassing the model entirely.
Unlike KV caching, semantic caching operates on approximate matches rather than exact reuse, so a small accuracy trade-off is possible, and similarity thresholds should be tuned carefully.
1. Prompt/Context Caching: Provider-side (e.g., via API parameters); caches stable prefixes across sessions.
2. These layers stack: KV caching always runs within a request; prefix and semantic caching extend reuse across requests.
Every enterprise AI workflow carries a hidden tax: static context. System instructions, domain knowledge, compliance frameworks, and product documentation are sent with every query, even when they have not changed in months.
At low query volumes, the cost is tolerable. At scale, it becomes the single largest line item on your AI infrastructure bill - as inference-driven workloads now dominate GPU spend, according to analyses of AI infrastructure cost dynamics.
Inference caching eliminates this tax by storing the computed state of stable content after the first pass. Subsequent queries that share the same context prefix skip recomputation entirely and pull directly from the cache, at a fraction of the original cost. The efficiency gains are real and immediate.
But realizing them at enterprise scale requires answering three questions that no off-the-shelf caching layer can answer on its own:
1. Which content is stable enough to cache safely, and which changes often enough to bypass the cache?
2. How do you partition context so that stable and dynamic content never contaminates each other?
3. How do you invalidate stale cache entries automatically when underlying documents change?
These are infrastructure questions, not just caching questions—and they are exactly what Knolli is built to address.
Inference caching looks perfect in the lab: repeat a prompt, hit 100% cache, and watch costs drop. Production quickly breaks that illusion for four predictable reasons.
1. Content Stability is a Black Box
Without metadata on update patterns, every document appears cache-worthy. Over-caching risks stale responses (e.g., outdated pricing in e-commerce bots), while under-caching forfeits savings.
Root cause: Many ingestion pipelines lack version tracking or historical signals. A compliance doc updated quarterly looks identical to daily news feeds.
Industry fix: Compute stability scores at ingest using factors like last-modified timestamps, edit velocity, and domain heuristics (e.g., "legal" = high stability).
2. Static and Dynamic Content Contaminate Each Other
Queries blend stable prefixes (shared knowledge) with dynamic suffixes (user history, real-time data). If mixed, caches become query-specific and hit rates can drop significantly.
Example: A customer support query starts with product docs (static) but appends chat history (volatile). Naive caching silos the entire prompt.
Architectural solution: Enforce prefix-suffix separation via metadata-driven retrieval, caching only the shared stable head.
3. Invalidation Is Manual and Error-Prone
Documents evolve—new policies, spec revisions, and knowledge refreshes. Manual cache purges miss entries, leading to "zombie" stale data, or widespread flushes that erase valid caches.
Scale nightmare: At 10,000+ documents, tracking dependencies manually is impossible.
Proven approach: Bind invalidation to document versioning systems, propagating changes to affected partitions automatically.
4. Multi-Tenant Risks Amplify Everything
Enterprises run dozens of isolated workflows (tenants). Shared caches can leak sensitive data across boundaries without granular controls.
Compliance risk: Missing audit trails for who accessed what cached state.
Enterprise standard: Extend RBAC to cache keys, ensuring strict tenant isolation.
These pitfalls explain why many pilots fizzle: caching promises evaporate under real workloads and scale.
Knolli targets the static context tax described above by turning enterprise knowledge into ready-to-use AI copilots that can reuse and orchestrate content intelligently.
The platform sits between your documents and LLMs, acting as an opinionated orchestration layer that can surface stable knowledge, secure it with role-based controls, and keep it updated as source content evolves. This approach aligns with modern enterprise AI infrastructure strategies, which emphasize metadata-driven optimization of inference for large knowledge bases.
To better understand model efficiency in such systems, it’s worth exploring how small language models (SLMs) differ from large language models.
The following is an illustrative breakdown based on typical enterprise RAG workloads (actual figures vary by model, provider, and context structure):
A knowledge-copilot layer like Knolli can help enterprises realize similar patterns by orchestrating stable prefixes and dynamic suffixes safely, aligning closely with how AI orchestration tools for enterprise manage complex AI workflows.
Inference caching is not a standalone tactic; it compounds with quantization (4-bit models), batching, and distillation. Prioritize caching first: it delivers the highest ROI for prefix-heavy workloads. Many vendors, including cloud-based model-serving platforms such as AWS SageMaker, now bake in KV caching, but they do not provide metadata-driven caching out of the box. This is where a knowledge-copilot platform like Knolli steps in: it handles the hard work of document indexing, versioning, and access control, so enterprises can apply caching more safely and at scale.
1. Day 1: Audit logs for prefix patterns.
2. Week 1: Deploy metadata ingest.
3. Week 2: Enable caching on top queries.
4. Ongoing: Monitor hit rates and iterate partitions.
Expect measurable savings in Month 1, maturing to 80%+ for many workloads as hit rates stabilize—a level consistent with industry-reported inference efficiency gains for well-optimized LLM serving stacks.
DIY caching demands engineering months on metadata pipelines. Off-the-shelf solutions (e.g., Redis-based AI caches) miss the stability and invalidation intelligence needed for enterprise workloads.
Knolli delivers production-ready, auto-configuring, auditable, and compliant infrastructure for AI copilots, specifically designed for high-volume, multi-tenant-like environments. This is particularly relevant for organizations managing 10,000+ documents and dozens of distinct query patterns under strict zero-stale-tolerance requirements, as discussed in broader AI infrastructure cost-management analyses.
Every week without inference caching is another week of paying full price for context your model has already seen. Knolli's metadata-driven platform is built to change that with enterprise-grade isolation, automatic invalidation, and deployments that go live in 3 to 5 business days.
The enterprises that act now lock in a compounding cost advantage. Those who wait keep compounding waste.
How does a platform like Knolli determine which content is safe to cache?
By ingesting metadata such as update frequency, version signals, and domain context, a knowledge-copilot layer can automatically flag high-stability content for reuse, while letting volatile content bypass aggressive caching—without requiring manual configuration.
What happens when a source document is updated?
When a document changes, versioned knowledge systems can propagate updates to downstream copilots, triggering re-indexing or re-caching of affected content, with audit-ready activity logs to track changes over time, similar to how versioned document management systems enforce consistency.
How does Knolli handle data security in multi-tenant environments?
Knolli is built with enterprise-grade security and governance in mind, supporting role-based access controls and isolated data environments so that each tenant's context remains siloed and compliant with financial, legal, and healthcare requirements.
Does Knolli work alongside existing data management platforms?
Yes. Knolli integrates via connectors with existing ECMs, cloud storage, and custom APIs, supporting common enterprise tools and workflows. Most organizations can get their copilots operational within 3 to 5 business days.
How quickly can enterprises expect to see cost savings after enabling inference caching?
Most clients see measurable reductions in infrastructure spend within the first week. High-frequency workflows on stable knowledge bases typically achieve the steepest savings earliest, with costs continuing to compound downward as cache hit rates mature over time.
